皆さん、こんにちは。
あなたが、インターネットを見る時に、最初に開くサイトはなんでしょうか?
「Google」や「Yahoo!Japan」がトップページに登録されているという方も多いのではないでしょうか。
今や、インターネットを利用するためには、「Google」や「Yahoo!」、「Bing」といった「検索エンジン」が必要不可欠なものとなっています。
分からない事や気になる事を入力するだけで、サイトの一覧を表示してくれる「検索エンジン」はとても便利なものですよね。
ですが、その『検索エンジンの仕組み』については、意外と知られていません。
無限に広がる情報の海であるインターネットから、必要な情報を瞬時に表示してしまう「検索エンジン」について徹底的に解説します。
検索エンジンとは?
皆さんがインターネットを開き、検索をする際に検索キーワードを打ちますよね。
その時に検索キーワードに基づいたページが表示されると思います。
では、なぜ皆さんが欲しいと思っている情報が即座に表示されるのでしょうか?
この仕組みこそが検索エンジンです。
皆さんが「欲しい!」と思った内容と関連性が高く、最もマッチングしたと思われるウェブサイトや、ブログのページをランキングにして表示してくれているんですね。
そのため、皆さんは出たきた内容から順番に探していけば良いだけ。
インターネットでは欲しいと思った内容が即座に出てくるので、パソコンや、スマートフォンを一台持っているだけで、何百万ページに及ぶ辞書を持ち歩いているのと同じ意味になります。
検索エンジンの始まりと歴史
では、検索エンジンの始まりを見てみましょう。
世界初の検索エンジンは、1990年代にカナダにあるマギル大学の学生が開発した「Archie」が最有力視されています。
archie(アーキー、アーチー)は、FTPサーバのアーカイブの索引を作り、特定のファイルを検索できるようにした、クライアント・サーバ型システム。史上初のインターネット検索エンジンと呼べるものである。 なお、archieが検索するのはファイル名であり、ファイルの内容ではない。
1990年にモントリオールのマギル大学の学生が最初の実装を開発した。 初期のarchieは単純にFTPサーバに接続してファイルの一覧を取得し(サーバに負荷をかけないよう、月に一度程度)、UNIXのgrepコマンドで検索していた。 後に、より効率のよいフロントエンド・バックエンドが開発され、archieは単なるローカルのツールにとどまらず、インターネット上のいくつものサイトで提供される人気の高いサービスとなった。 そのようなarchieサーバは、専用クライアント(archieやxarchieなど)、Telnet、電子メール、WWWなどさまざまな方法でアクセスできるようになっていた。
archieという名前はarchiveに由来しているが、Archieという名前の漫画も連想させる。 これはもともと意図したものではないが、これに影響されて、この漫画の登場人物のJugheadとVeronicaがGopherの検索システムの名前に使われた。
今日ではWWWの検索のほうがはるかに便利であり、稼動しているarchieサーバはほとんどない。
出典:Wikipedia
インターネット上に存在している、あるファイル名を指定して検索するという、とても原始的なプログラムでした。
90年代後半には、Yahoo!、goo、MSNといった検索サイトがいくつも誕生し、1998年には、いよいよGoogleが誕生します。
IT業界の成長とパソコン・携帯電話の普及と共に、検索エンジンサイトも急激に発展し、今のように一般的な存在へと変化していきました。
検索エンジンの大元となるシステムが出来てから20年以上の時を経た現在、Googleの検索エンジンが圧倒的な機能と利便性で、世界のトップシェアを誇っています。
ちなみに日本ではYahoo!が一位で、Googleが2位で、この2つだけで90%以上の利用率になっています。
しかし、Yahoo!の検索システムはGoogleと全く同じものが使われています。そのため、Googleの検索対策がそのままYahoo!対策にもなってしまうんですね。
検索エンジンの使われ方
検索エンジンとは、『インターネット上のサイトやコンテンツを調べるサービス』の事です。
現在の日本ではこの3つが大きく利用されています。
- Yahoo!
- Bing
今では、当たり前のように利用していますよね。
そんな検索エンジンは、大きく3つの仕組みで成り立っています。
- ネット上の情報のデータベース化
- データベース内情報の優先順位付け
- 検索キーワードに合わせた検索結果の表示
これら3つの異なるプログラムが連携しつつ、検索エンジンは機能しています。
データベース作成とクローラー
ネット上には無限ともいえる程、サイトやコンテンツ・情報がありふれています。
ここで1番目のネット上の情報のデータベース化に『クローラー』が大活躍しているのです。
検索エンジンも元データとなる『データベース』が無ければ、検索結果を出しようがありません。
そこで、ネット上のあらゆる情報を蓄積するために『クローラー』というシステムが用いられるようになったのです。
特に、検索エンジンにおいては、各企業によって専用のクローラーが開発され、日々世界中のウェブサイト構造を解析し、収集し続けています。
データベースとは何なのか?
どうしてデータベースを収集していく必要があるかというと、例えば百科事典でいうと欲しい情報を探す時、目次を見てから探しませんか?
普段のユーザーとして利用してみると、検索エンジンは、キーワードを入力する度に直接インターネットから情報を調べ出しているかのように、感じるかもしれません。
しかし、検索エンジンは、あらかじめインターネット上から大量の情報を集めておき、膨大な自作データベースを構築しています。
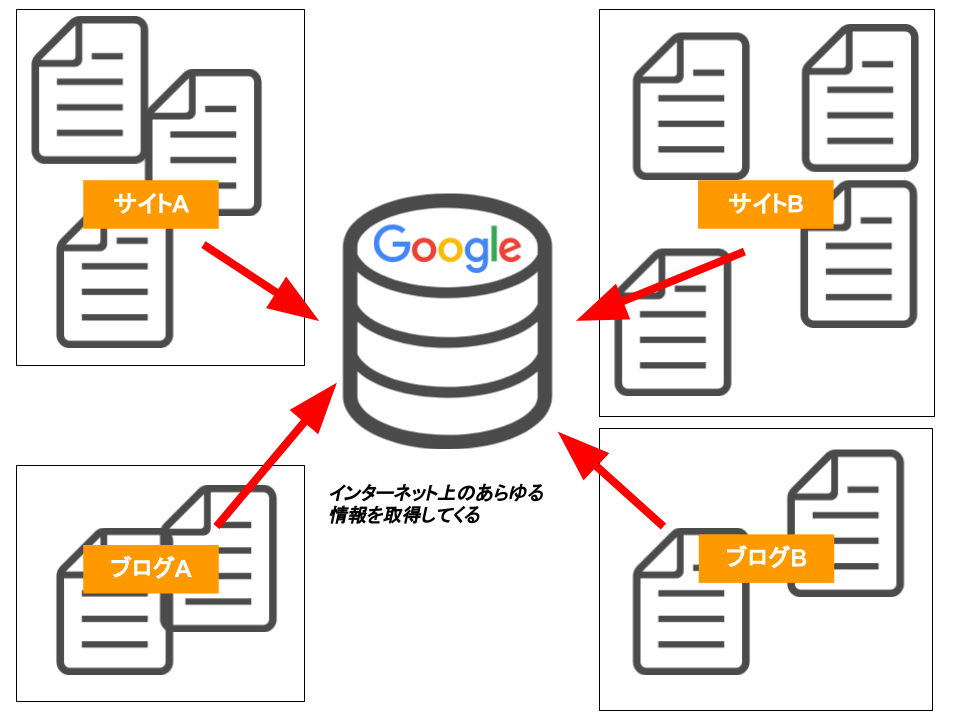
検索する際には、そのデータベースから必要な情報を調べ、ユーザーに適切なページを提示しているのです。
つまり検索したい情報を瞬時に探し出すために情報を収集していると言っても過言ではありません。
この目次を作るためには、情報を自分のデータの中に入れなければ作れないのですね。
この目次のことを『インデックス』と呼び、日々収集し続けています。
【主に収集される情報】
- タイトル
- 本文
- 投稿日時・更新日時
- カテゴリ
- タグ
- 検索時の説明文
- アイキャッチ画像
- 著者名
など…。
検索エンジンの情報収集の仕組み
日常的に利用されている検索エンジンですが、その情報収集の仕組みはどうなっているのか?
実は検索エンジンをしっかり理解しているウェブデザイナーは少ないのです。もし、あなたがウェブに関わる仕事をしているならば、ぜひ理解しておいてください。
「検索エンジン」というシステムは、インターネットの情報を集めるプログラム、情報の優先度を順位付けするプログラムなど、いくつかのプログラムが組み込まれる事で成り立っています。
その仕組みは、主に3つに分類されます。
- クローラー … ウェブページを巡回し、ページやコンテンツを解析し、情報を集める。
- インデクサー … クローラーが収集したデータをコピーし、データベースとして蓄積していく。
- サーチャー … データベース内から、検索キーワードに関係した情報を抽出し、優先度順にランキング付けをする。
これは先程の検索エンジンの使われ方にて説明した、3つの項目を行う機能の名称です。
では、3つの機能を詳しく説明しましょう。
①クローラー
検索エンジンには、まず検索の土台となるデータベースが必要となります。
検索をする度に、情報量が無限に広がっているインターネットから人力で情報を集めるのは、非常に労力がかかってしまいます。
そのため、検索エンジンではインターネット上の情報を反映した巨大なデータベースを有しています。
そのデータベースを作成するために使われるプログラムこそが『クローラー』です。
クローラーの情報収集の仕方は、リンクを辿っていく事です。
ページの外部リンクや内部リンクを隅々までたどる事で、網目のようなインターネットの把握に努めています。
そのページを這っているような状況から、『這うもの』を意味する『クローラー』と呼ばれています。
クローラーにページ内の情報を隅々まで持ち帰ってもらうために、巡回効率を高めることをクローラビリティと言います。
クローラビリティを改善し、SEO対策をする方法はこちらの記事を参考にしてください。

②インデクサー
クローラーによって集められたページの情報は、次のプログラム『インデクサー』へと移されます。
『インデクサー』の主な作業は、『データの蓄積』と『索引付け』です。
まず、インデクサーは、クローラーが集めたページの情報を丸々コピーします。コピーをし続けることで、データベースを大きくし、最新の情報に更新しています。
ただし、クローラーが集めてくるデータは、HTMLという情報のみです。
情報を整理し直さなければ、検索結果として表示することはできないんですね。
このHTMLを適切な形に変換し、データベースに蓄積するのをインデクサーがやってくれています。
その蓄積の際に、索引のデータを追加します。これが『インデックスされた』という状態です。
検索エンジンとして、最終的に検索がしやすいように、ページ情報や内容の特徴を紐づけているのです。
インデックスされたか調べる方法
site:ページのURL で検索エンジンに登録されたかどうか調べることが可能です。
③サーチャー
インデクサーによって構築されたデータベースは、『サーチャー』によって検索が出来る状態に整えられます。
サーチャーの主な役割はユーザーが求めている情報にピッタリの情報を提供すること。
『インデクサー』の主な作業は、キーワードに対応した情報の『抽出』と『索引化』でした。
その索引と検索エンジンごとに定められたアルゴリズムに基づいて、検索キーワードに相応しいページ情報を選び出し、そのページ情報をランキング付けしていくのです。
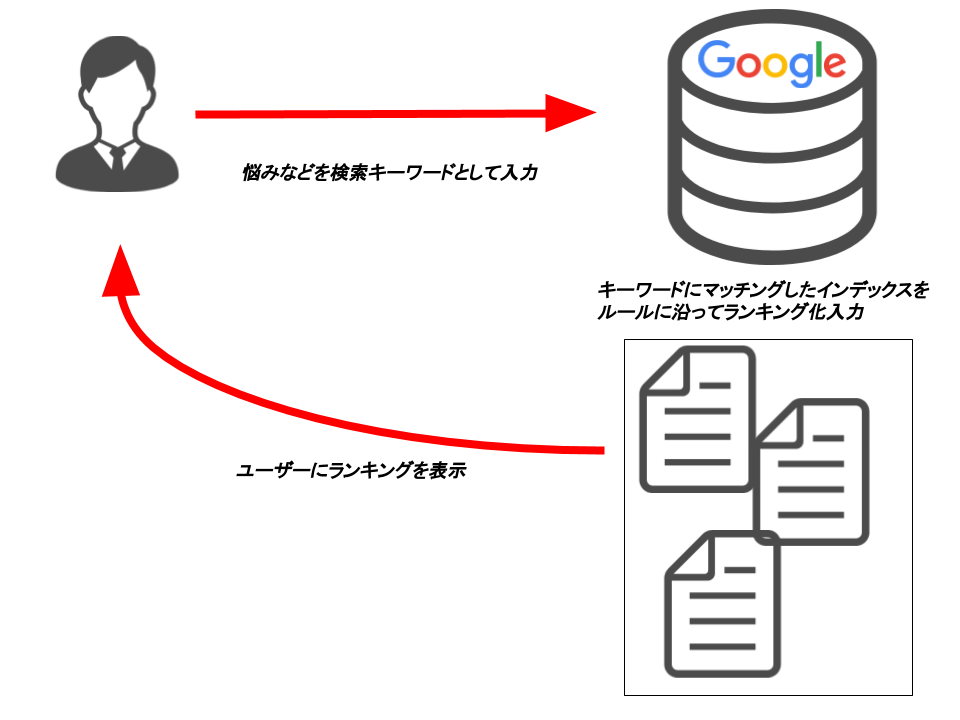
この内容をスコアリングと言ったりもします。
このランキング付けの精度こそ、検索エンジンの質を決めているといっても過言ではありません。
ランキング付けに使うルールは、Googleからは公開されていませんが、実際には200以上あると言われており、質を保つために厳正なチェックが行われています。
このように、検索エンジンの仕組みは、
「ページ情報の収集」⇒「ページ情報の索引付け」⇒「ページ情報と検索キーワードのマッチング」⇒「ページ情報のランキング付け」
という流れで、行われているのです。
ユーザーの求めているニーズを知るには検索キーワードボリューム分析が必須です。
Pasolackではキーワードプランナーではなく、UberSuggestというサービスをオススメしています。
▼詳しくはこちらの記事を参考にどうぞ。

まとめ:検索エンジンの仕組みには4つの流れがある
いかがでしたでしょうか?
検索エンジンと一口に言っても、人工知能が3つあり、4つの作業を分担して行っていることが分かりましたね。

- ページ情報の収集(クローラー)
- ページ情報の索引付け(インデクサー)
- ページ情報と検索キーワードのマッチング(サーチャー)
- ページ情報のランキング付け(サーチャー)
この流れを理解し、どんな情報を元にランキング付けされているのか?
それを知ることがSEO対策の基本となります。
皆さんの知識に何かしら貢献できたならば幸いです。
他にも検索エンジン、クローラーについてや、SEO対策の情報をまとめているので、ぜひご覧ください。